The interface of Kadis aims to assist users to make a query through web browser by means of Internet techniques. It exploits the client-server architecture. The data are stored at the server side, and all processing work, such as query processing, data processing etc. is also done at the side of server. The user reads data and produces the query at the side of client through a web browser, for the moment only IE is completely supported. The basic operating procedure is present as a flow-chart in the following figure.
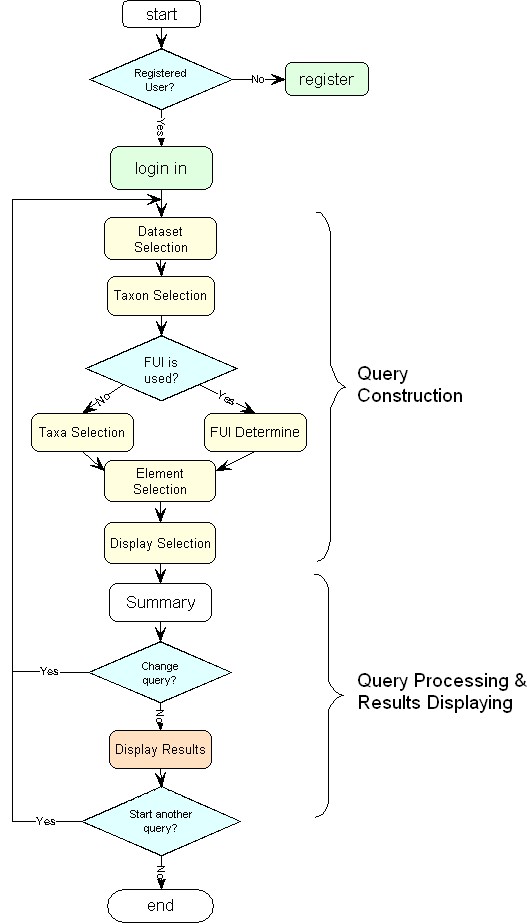
Below, we will give a detailed description of the very procedure.
1. There are two kinds of data used here, one is to do with the information collected from the original dataset of archeology, and the other is meta-data used to describe the relationships hiding in the former.
2. Two kinds of format are used to store the data, one is mysql, and the other is XML. So the mysql server is used in our project, which stores and manages the data related to the users' profiles, the original data from excel files, and those intermediary assistant to the query and display of data. With the natural tree-structure of XML, we construct the hierarchical structure of concepts in the ontology of each dataset. These XML files help us to display the archeological concepts hold in the original dataset in a tree-similar way (we can also call it hierarchical structure).
3. In the implementation, PHP language is used at the side of server, and Javascript is at the client side. I have to say, there are not many comments in the code. I also believe it's not easily to be maintained. I would rather take this very implementation as a temporary one, which is supposed to be constructed from the scratch if the project KADIS is formally and financially supported at last.
No comments:
Post a Comment