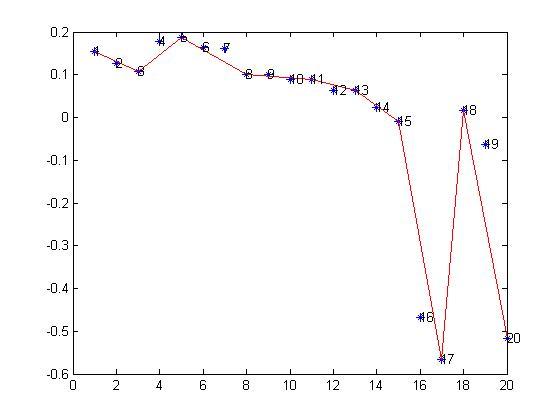
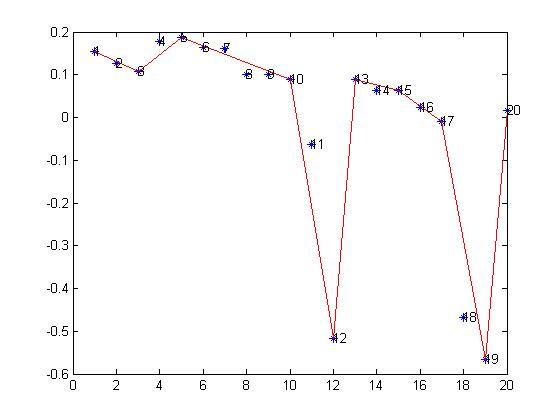
When I used the new algorithm (including curve segments combination and topic segments identification) to make experiments on the same dataset, I found that it is almost impossible to find some cases related to the 'interruptted' patterns. In the morning, I started to try larger thresholds. It still doesn't work. However, I met with a very different situation from the previous. Suddenly, I had a new idea to decide the boundaries among topic segments.
When I used a small threshold value for the 'dominated/dominant' pattern, the patterns of results construct an irregular sequence, that is, the 'dominated/dominant' patterns and the 'drifting' patterns interleave in a random manner. If I followed my previous scheme to get the boundaries in the squence, I have to analyze each segment one by one. But when I increased the value of threshold, some interesting changes happen. Some 'dominant/dominated' patterns come out in a consecutive way, that means, they could be combined together. According to the plot for all entries, it looks impossible or meaningless to be classified them to be 'dominated/dominant' patterns, whick LOOK obviously kind of 'drifting' pattern. But the result is so regular that it could produce much better boundaries if we combine the consecutive segments together. It is time to split the pattern analysis and the plot, although not so completely.
If the new approach to decide boundaries are proved useful, we can get at least two benefits. On one hand, the combined 'dominated/dominant' pattern topic segments make it possible to construct a hierarchical structure about the content of entries, although it might not be realistic for the moment. On the other hand, according to current results, the combination of topic segments could make improvement on the segmentation of topic segments. Furturemore, it could identify the main tendency of entries, i.e., the general topic development patterns in the entries.
By the way, this result made me reconsider the role of plots we got from the curve segmentation. We draw the curve in a two-dimensional plane, but the two dimensions are different in terms of scales. The X axis describes the sequence number of entries, which is measured by discreted numbers. Whereas the Y axis records the value of each entry, the value is kind of measure of 'content' in each entry. When we use curve segmentation algorithm to approximate the entries in the plane, we treat the two dimensions equally without considering their difference, but we should do so. :(